Code#
Note
Link to JIRA: https://aeadataeditors.atlassian.net/jira (requires login).
Now that you have pulled everything together, you will inspect the authors’ README, and do a first analysis of the code and the necessary data.
Verifying completeness of the README#
The first section of the Replication report is titled “General”. Here you want to verify how complete the README is.
Go through the entire README, and compare both to the template README and the sections in the General section.
Check off the sections for which you appear to have information.
Leave blank the sections that are either not provided, or that are empty
In JIRA, identify the question called “
DCAF_README_compliant”.If all or most of the sections are in the same order, and are filled with meaningful information, then check
FullyIf information is provided, but in different order, or only mostly, mark “
Content only”.If very little of the information is provided, mark it as “
No”
List of Data Sources#
Now you will establish a list of data sources used.
Please check the Data and Code Availability Form.
The form should be attached in the JIRA ticket.
In area 2 of the screen, choose
DCAF.Open the Data and Code Availability Form, and check if all blanks are filled out.
Once you checked the form, and in particular, if the checkbox next to “README” is checked, choose “
Yes” from the dropdown menu ofDCAF_README_checkedcell.If the answer to the following question at the bottom of the form is “Yes”, then, choose “
Yes” from the dropdown menu ofDCAF_Access_Restrictions. Otherwise, choose “No”. “Is any of the data used in this manuscript subject to access restrictions?”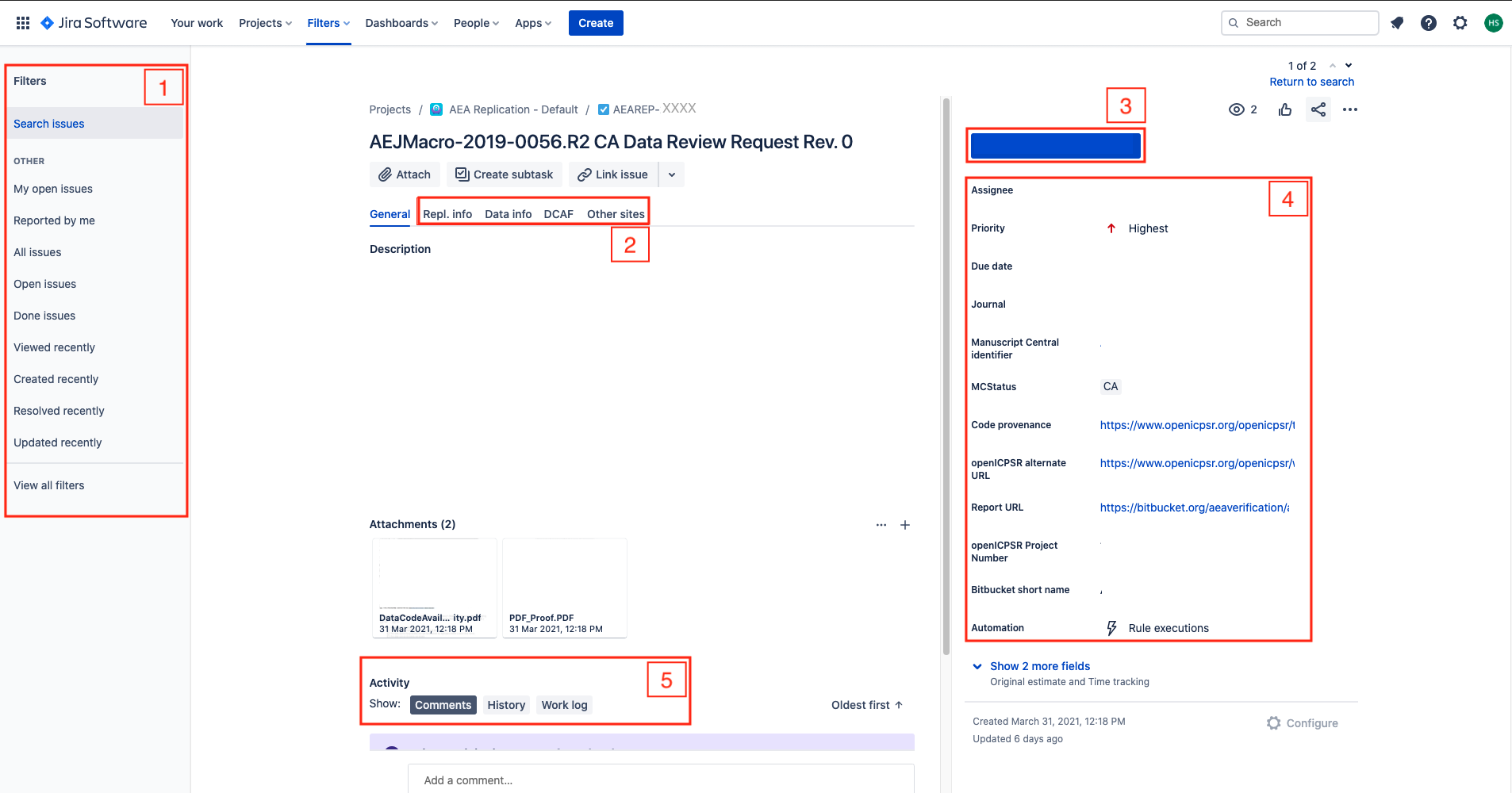
Note
What is the difference between a “data source” and a “dataset” or “data file”?
A data source is more general. A data source may provide multiple data files. One example is the “Current Population Survey”.
A dataset or data file is a single file that appears in the replication package. An example is “
data_cps.dta”, which is presumably the data file containing the Current Population Survey.
For this section, you should list data sources.
From the README provided by the authors, the data section of the article itself, or an appendix, establish a list of data sources used in the article. For each data source
write the corresponding
Data descriptionsection of REPLICATION.md. This should provide detail about the datasetsIf data are cited, copy and past the citation to the replication report, clarify which one you are referring to. Be sure to check AEA Sample References and the additional guidance to be sure it is a data citation, and not a citation to an article or a document describing the data!
check any provided URL, and verify if there is a “Data Use Agreement”, “Citation requirement”, “License” on the web page. Check any such data use agreement for conditions. These may require that the authors cite a particular paper, or cite the data in a particular way (check this), or that the authors may not actually redistribute (provide) the data (check this!). If you have doubts, check with your supervisor.
Check that there is enough information to obtain the data in the README. Based on the README, you should be able to find, on the linked website, the data that you would need. (Ignore at this point that the data might be provided)
Add the list of data sources to the repository by committing the preliminary version of the REPLICATION.md (
git add,git commit,git push)Fill out the
DataCitationSummaryfield indicating how many data citations are in order:all,some, ornone.Fill out the
Data ProvenancesectionAre the data in the openICPSR repository, or are they someplace else? “Various” is a legitimate answer if data are in various locations.
Please refer to Chapter 9 A guided walk through the Replication Report for more details about which data sources to include and how to assess the provided information.
Other information#
Have a look at the README again.
Is there information about Requirements?
Is there information about the software?
How long does the author say the code will run?
How much memory, or processors, does the code need?
This may tell you if you, or somebody else, will need to run the code, and whether CISER, or someplace else, is a good place to run the code.
Review of Code#
Now do a first pass through the code files provided:
Warning
Do NOT run any code yet!
review the code in detail.
In the template, you will find code-check.xlsx.
Use this to create a list of all Tables and Figures in the paper, and use this to guide you in REPLICATION.md.
Fill out the “Code Description” section of the REPLICATION.md
Provide some information about the program files (are there 3 Stata files? Are there 5 Matlab programs?). You will use this information to fill out the
Software Usedlater as well, but provide details here.You can use the file “
generated/programs-list.txtto help you here.
Did you have difficulty aligning the README with the files? Does the sequence suggested by the programs differ from what’s written in the README?
Are there files in the archive not explained in the README?
Copy-and-paste the code-check.xlsx into the code description part, listing the programs. Omit the “Reproduced?” Column in doing so. Use the Excel-to-Markdown plugin for VSCode.
This table will be pasted in under “Findings” again, with “Reproduced?” column, once code has been run.
Next fill out the following fields in the Jira ticket:
BITBUCKET SHORT NAME- if not already done earlier
Tip
Commit!
git commit 'Finished code section'
git push
You can now proceed to change the status to `Data`. As you select that transition, you will be asked various questions:
- [ ] `Software Used` Start typing the name of the software program you will use for the replication. Software that have been used in the past will show up as options (e.g. start typing "Stata" and you will see it pop up).
- [ ] `PROGRAMSEQUENCE` Does the README tell you the correct sequence for running the code?
- [ ] `PROGRAMSDOCUMENTATION` Are the provided programs well commented? Are they documented in the README?
- [ ] `PROGRAMSSTRUCTUREMANUAL` Does the README note any manual changes that you need to make to the code in order for it to run?