D Downloading Data
Most data we receive comes from pre-publication openICPSR deposits. However, they may sometimes be privately provided and are then stored on a secure shared drive, or they may come from other trusted repositories (e.g., Zenodo, Dataverse).
D.1 Using openICPSR Projects Prior to Publication
Typically the AEA Data Editor team will access code and data provided by authors that is stored on openICPSR.
Cornell replicators: You will need to set up an openICPSR account using your Cornell email.
D.1.1 Basics of openICPSR
- Authors will create a draft deposit that contains the replication archive for their paper.
- Each deposit is identified with a six digit number.
- You will download the project and commit the code (but not the data) files to the corresponding Bitbucket repo.
D.1.2 Downloading a project
- Log on to the openICPSR website by clicking on the
Code provenancelink in Jira - If you get an error, the project has probably not been shared with you. Contact your supervisor.
- If successfully logged on, you will be able to download the project from the “more” menu:
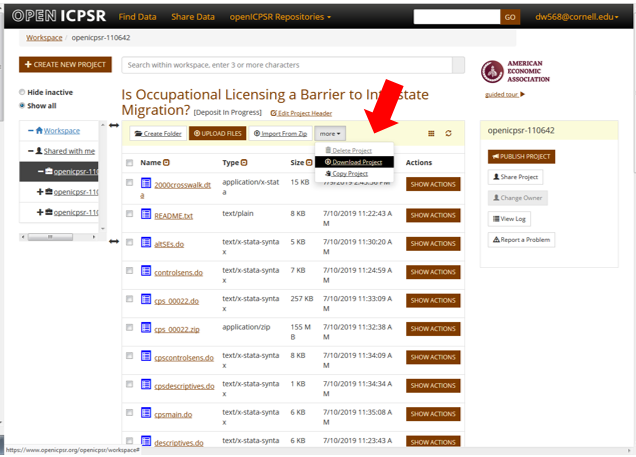
D.1.3 Reminders
Normally, none of the actions below are technically possible, but you should nevertheless follow these guidelines:
- Do not publish the openICPSR projects.
- Do not upload files to the projects.
- Do not share projects with others unless instructed otherwise.
- Do not share screenshots with others
See [Privacy] section about expectations on privacy.
D.2 Alternate sources of data
We sometimes encounter replication packages that reference Dataverse or Zotero. Download those as they are found on those sites. Extract them as you would the openICPSR downloads, with the directories named as follows:
- Dataverse: Use the latter part of the DOI. E.g., if the Dataverse package’s DOI is
https://doi.org/10.7910/DVN/RE5ZVI, name the directoryDVN-RE5ZVI. - Zenodo: Use the latter part of the DOI. E.g, if the Zenodo package’s DOI is
https://doi.org/10.5281/zenodo.7041706, name the directoryzenodo-7041706.
D.3 Accessing privately provided data
D.3.1 When there is privately provided data
In some cases, authors will provide us privately with data we cannot publish.
You will know where the data are by looking at the JIRA issue. You will often (but not always) see a subtask which we use to request the confidential data:

subtask for confidential data
You should then look into the “Data” tab for the field Working location of restricted data:

JIRA field for location: S:-3756-nda_Implicit
D.3.2 How to prepare privately provided data
- Log into CISER as usual. You should never need to run code elsewhere when data are restricted/privately provided.
- Open the File Explorer
- Under “
This PC”, click “Share (\\rschfs2x.ciserrsch.cornell.edu)” underNetwork Locations. This location is also available as “S:”. - Find the
LDILabfolder. (You should probably bookmark/ add to favorites) - Within that folder is the corresponding restricted access data (e.g.
aearep-3756-nda_Implicit)- If you cannot open the
LDILabfolder, contact the assistant to the Data Editor
- If you cannot open the
- If there is a ZIP file (looks like a folder, but is not), right-click and choose
Extract Allbefore working in the folder - Remember the full location. This should correspond to what is entered in to the JIRA field, e.g.,
S:\LDILab\aearep-3756-nda_Implicit.
D.3.3 How to use the data in this folder
There are two situations.
- The folder contains ONLY the confidential data. This should normally be the situation…
- The folder contains a copy of the openICPSR deposit, but with the confidential data included.
There are two ways to run code using the data in this folder:
- Run all programs within this folder, do not take the data out of this folder. However, you will need to transfer log files and output back to your regular “cloned” folder (i.e.
aearep-3756). - More robust, but a bit more work, is to modify the code to reference the confidential data every time it is called.
- In the
config.do, is a lineglobal sdrive "". Modify that line to readglobal sdrive "S:/LDILab/aearep-3756-nda_Implicit" - Run the code in its usual location. When the code encounters (absent) confidential data in the usual location, it will break/stop.
- Everywhere you encounter references to confidential data in the code, e.g.,
use "${datadir}/mysuper.dta", modify the code to reference the S-drive:use "${sdrive}/mysuper.dta. - commit all code modifications and log files as you normally would.
VERY IMPORTANT: You must treat these data as confidential, never remove them from CISER!