


Preserving Survey Data
2026-06-14

Consider the case of Gino

Francesca Gino
The case of Gino
- Several articles were investigated by third parties (Data Colada, in particular 1), and found to be problematic

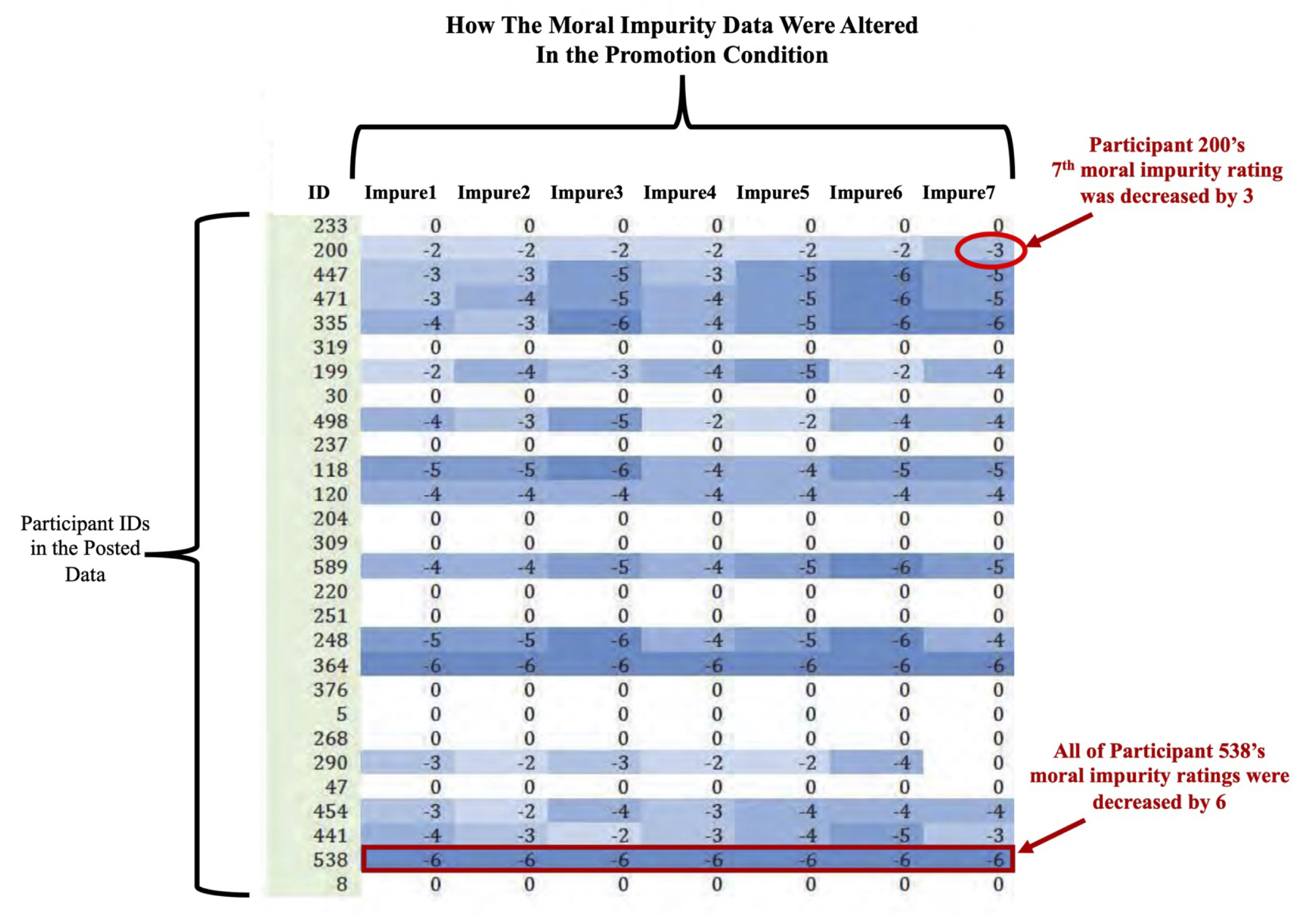
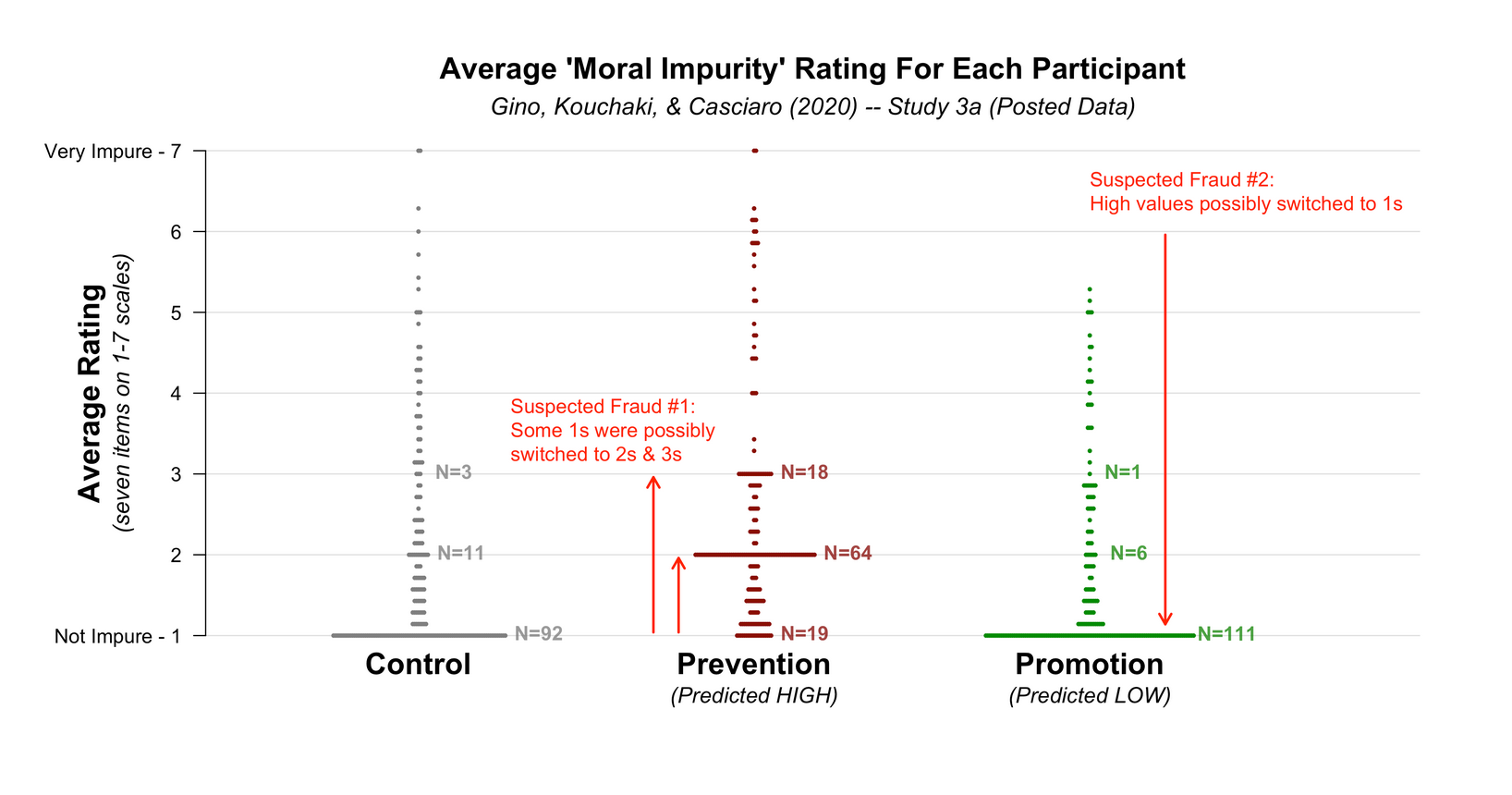
The case of Gino
- At least one of them had manipulated data AFTER it had been collected, BEFORE it had been analyzed.
Generic survey processing
Requiring transparency in academia
Where we are headed
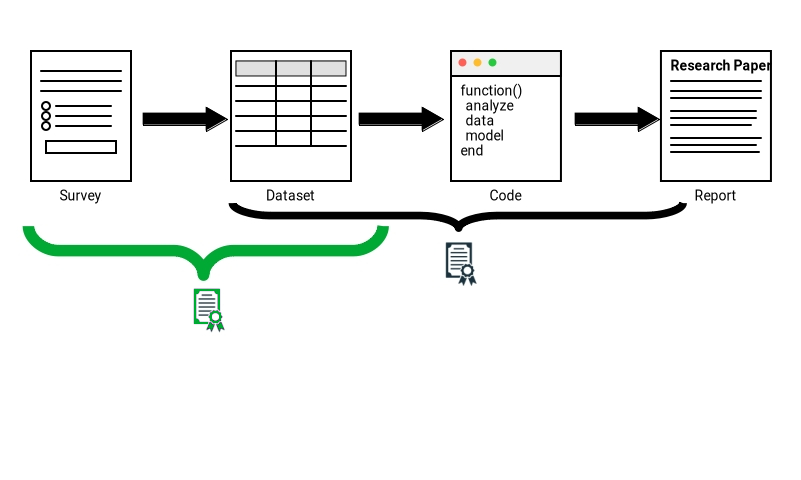
Verifying transparency in academia
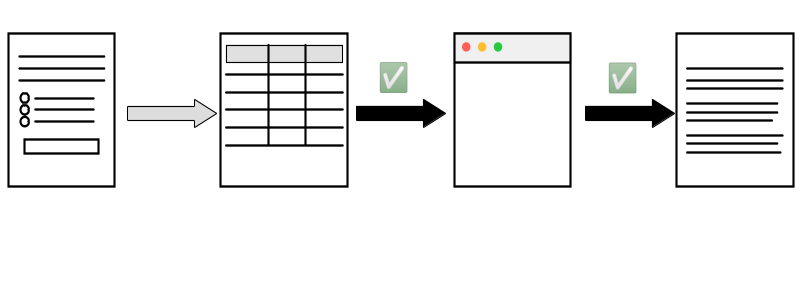
Which journals
- American Economic Association (8)
- Econometric Society (3)
- Canadian Journal of Economics (1)
- Royal Economic Society (2)
- Western Economic Association International (1)
- European Economic Association (1)
- Review of Economic Studies (1)
- Journal of the European Economic Association (1)
- Journal of Political Economy (3)
- American Journal of Political Science (1)
- American Political Science Review (1)

Verification by others
- Pre-publication: cascad

- Post-publication: Data Colada, Institute for Replication

Verification by institutions


Creating a survey in Qualtrics
You’ll typically have access to a Qualtrics account through your university or organization. Then it is easy to construct a survey using the web tool.
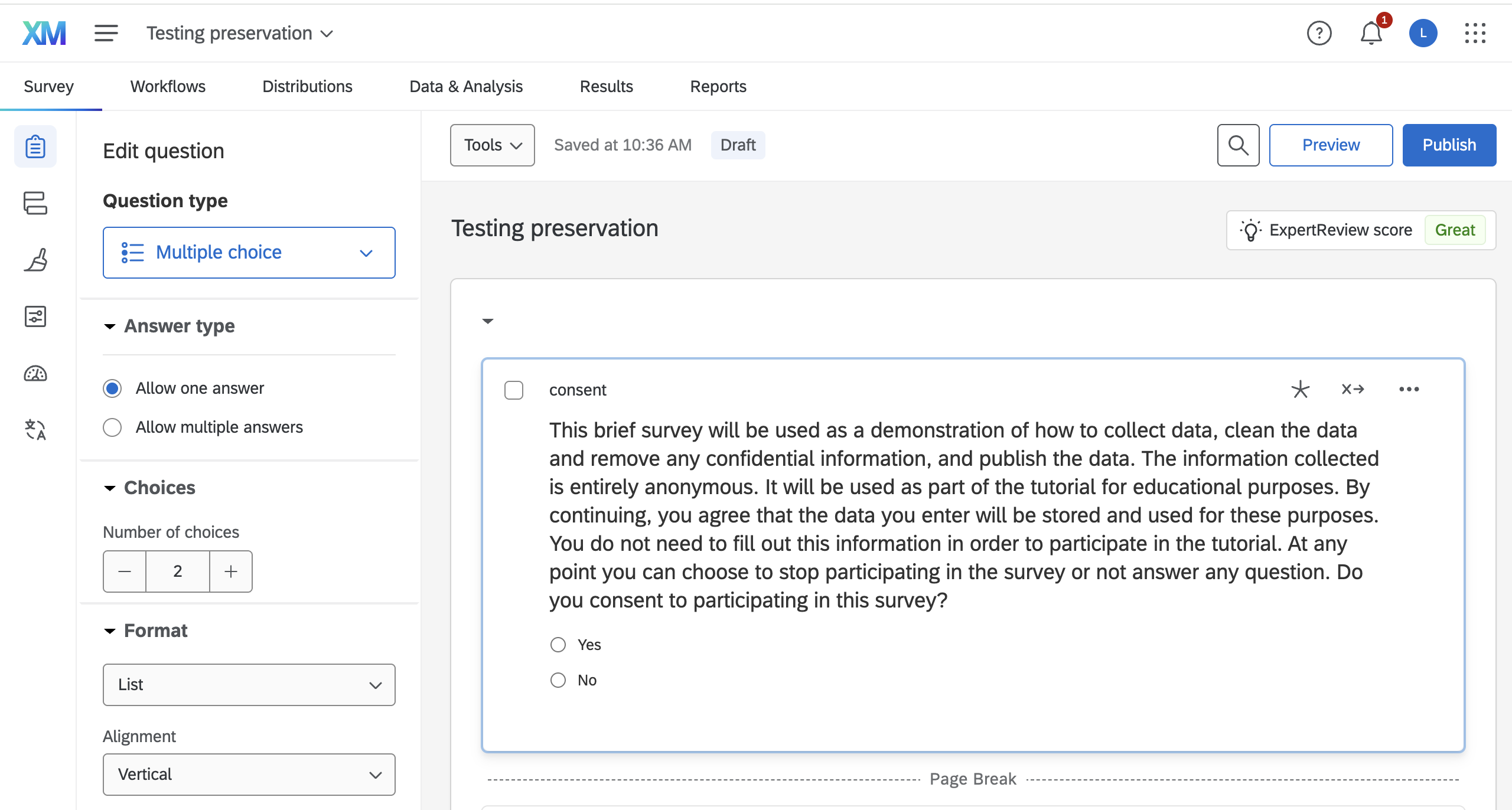
Survey responses in Qualtrics
Responses can be easily checked at a glance in the Data and Analytics tab. 🔒
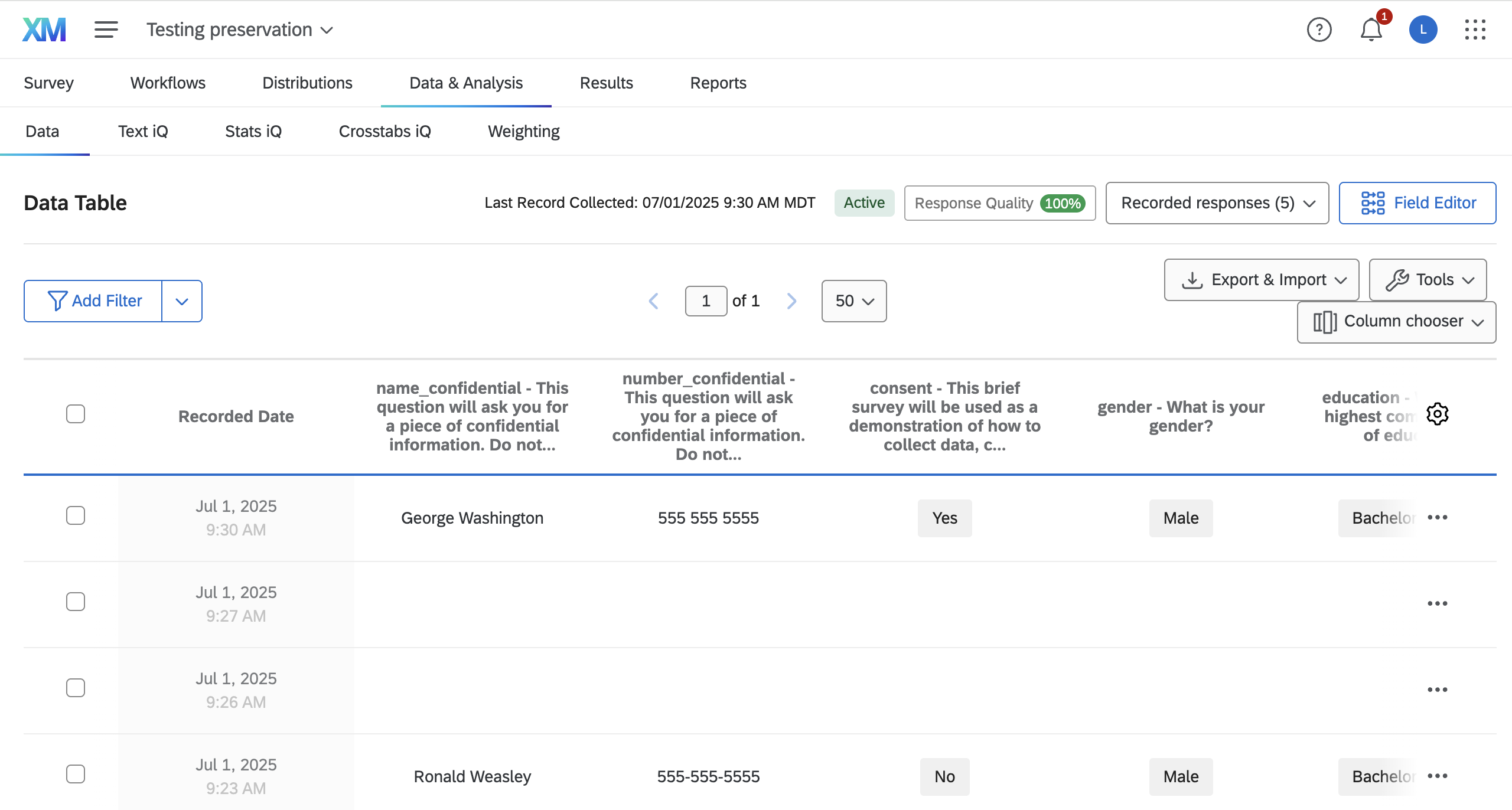
Downloading data
You can download data directly from this page
- If you do this only once, downloading manually is fine.
- Do it 2-3 times, you may want to program it!
Download options
You can download data directly from this page
- Do it 2-3 times, you may want to program it!
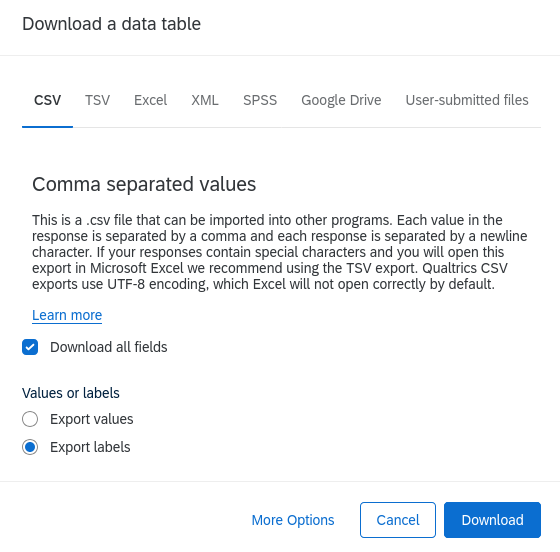
Credibility of the data flow
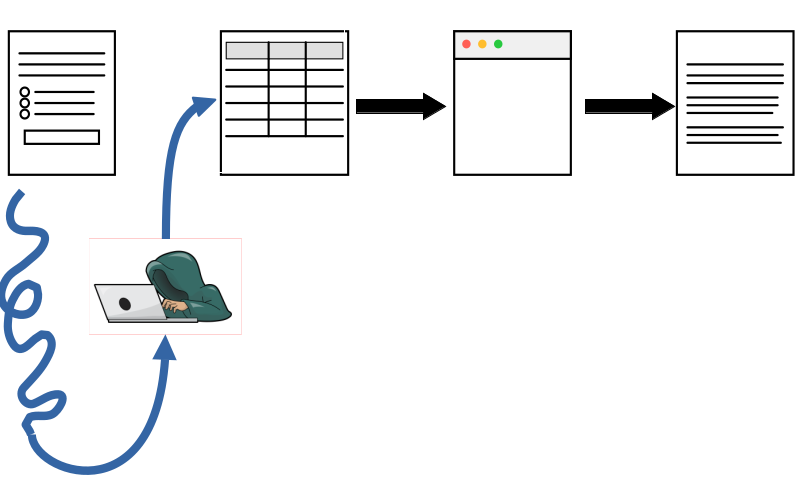
What could go wrong?
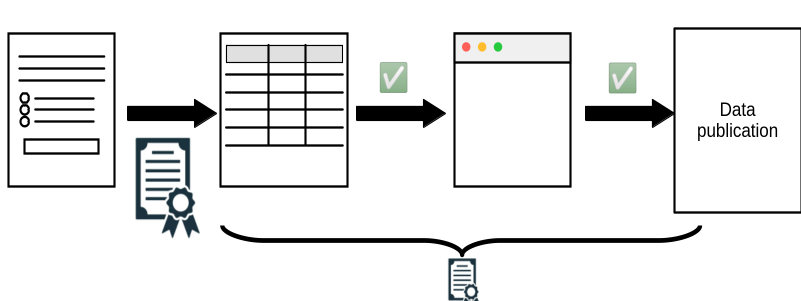
How to CERTIFY the full process?
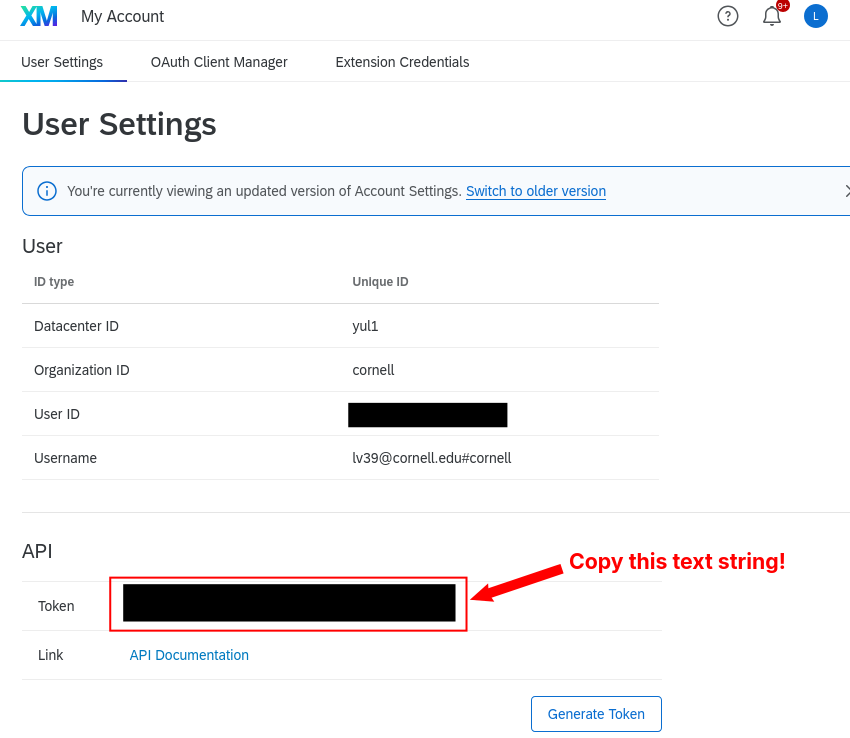
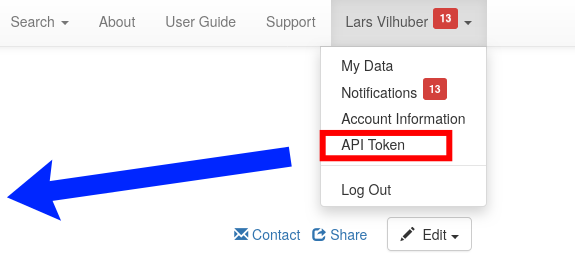
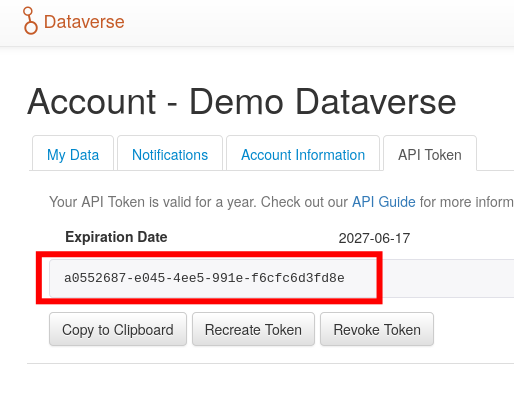
Qualtrics and API tokens.
An API token is assigned to your Qualtrics account. Where do you find it?
Credibility of Survey Data
- You run a study using the PSID. Do you trust the downloaded data?

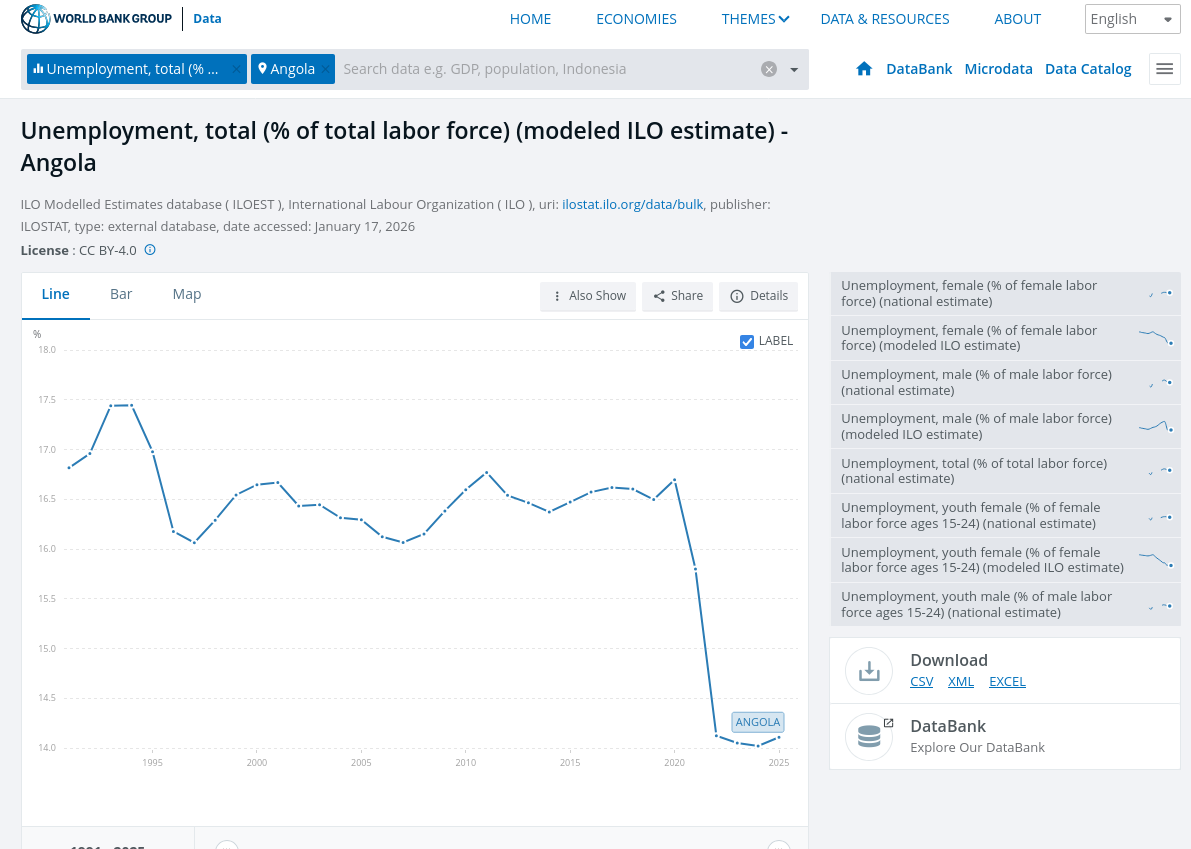
Credibility of Government Data
- You run a study using the PSID. Do you trust the downloaded data?
- You use unemployment data for Angola through World Bank Data Bank. Do you trust the downloaded data?
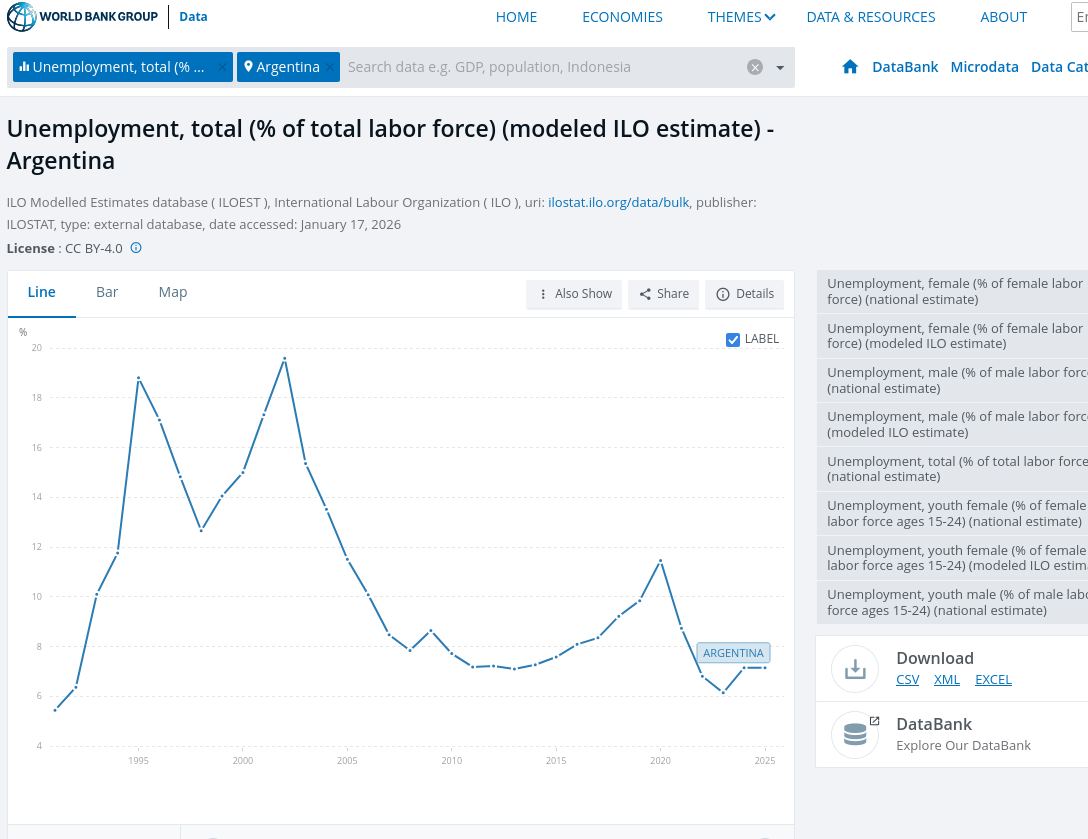
Credibility of Government Data
- You run a study using the PSID. Do you trust the downloaded data?
- You use unemployment data for Argentina through World Bank Data Bank. Do you trust the downloaded data?
Credibility of Government Data
- You run a study using the PSID. Do you trust the downloaded data?
- You use unemployment data for United States through World Bank Data Bank. Do you trust the downloaded data?
Credibility of Researcher provided data
- You run a study using the PSID. Do you trust the downloaded data?
- You use inflation data for Argentina through a research deposit on Dataverse. Do you trust the downloaded data?
Timing
Once you have registered your analysis plan - should the processing and analysis really change?
Once you have collected the data - is it really going to change?
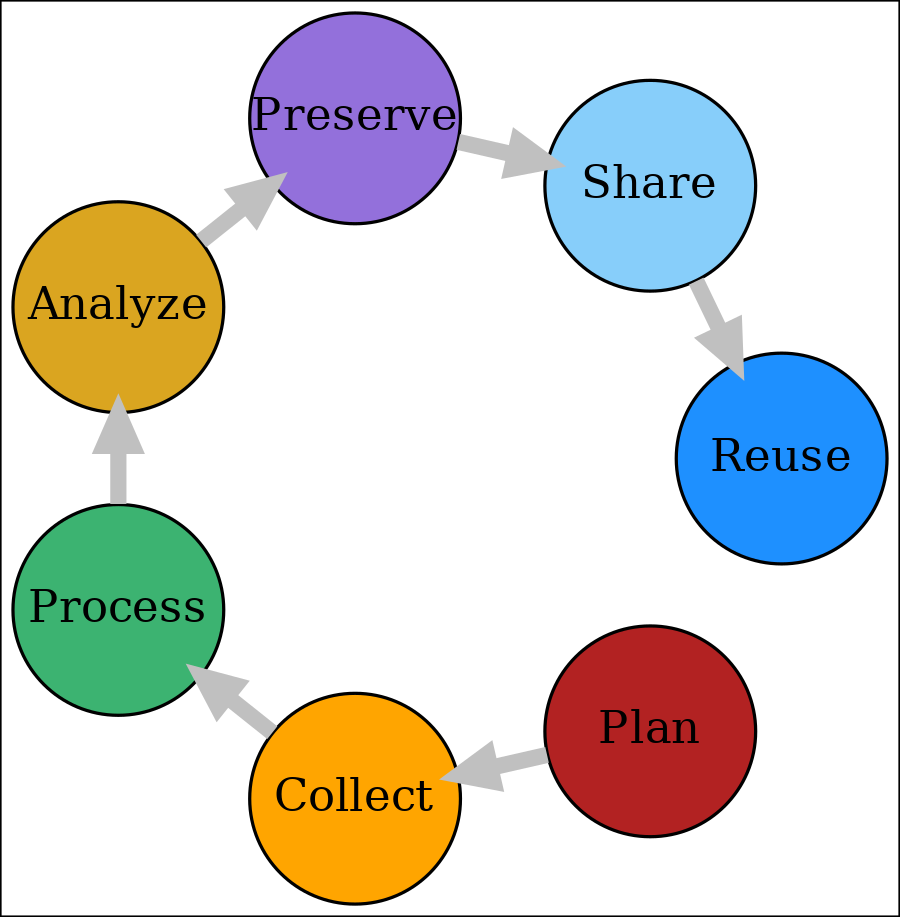
Modified Data and Workflow
Let’s consider the preservation part separately:
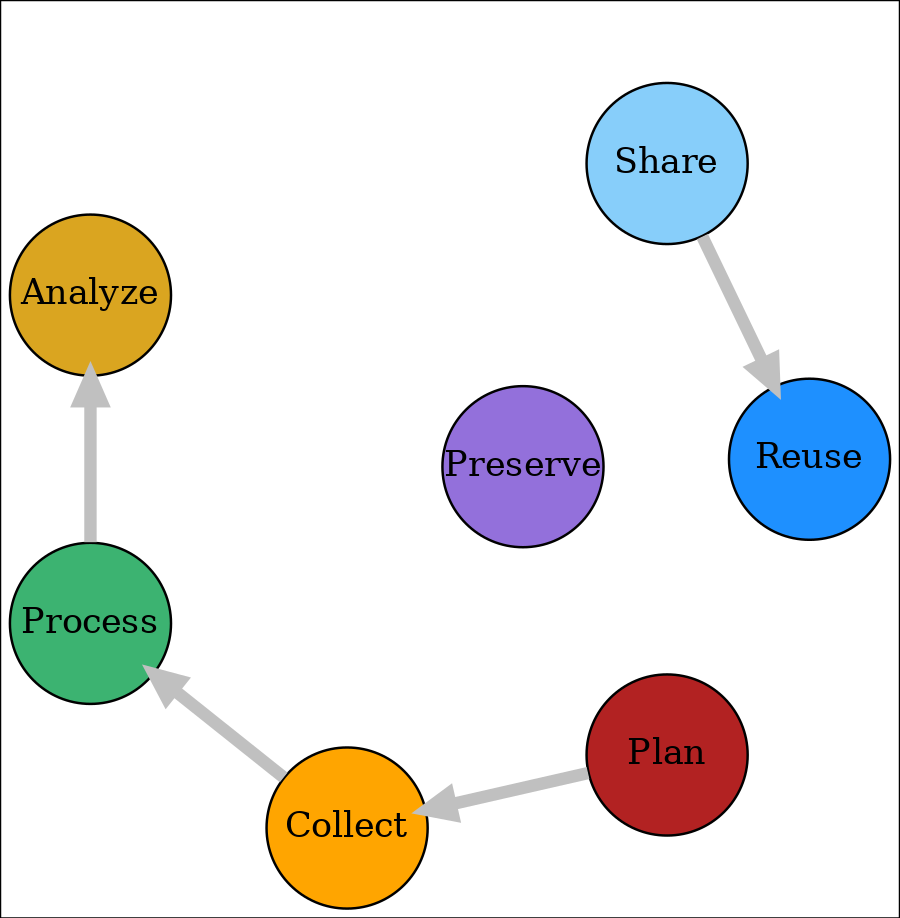
Modified Data and Workflow
Proposal:
- Preserve as you go

Modified Data and Workflow
Proposal:
- Preserve as you go
- Use what you preserve
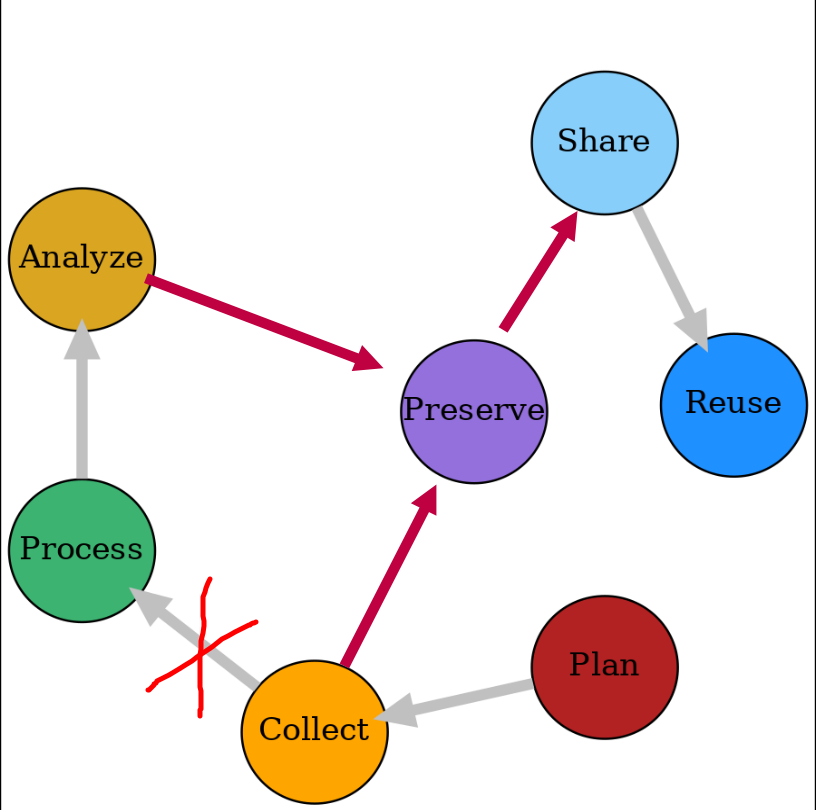
Modified Data and Workflow
Proposal:
- Preserve as you go
- Use what you preserve
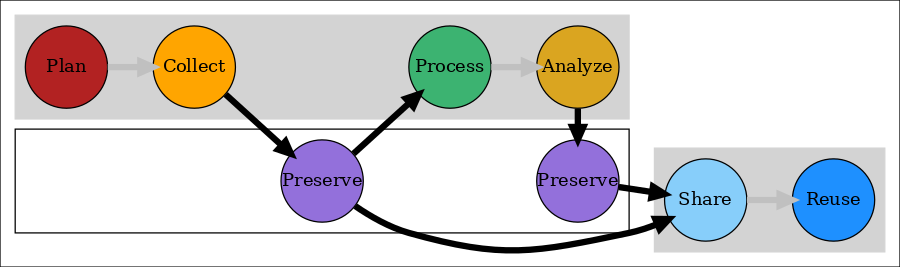
Preservation
- Preservation != publication, != sharing
- In fact, preservation may mean: not very accessible at all!
- Preservation is intended to maintain data for tens, even hundreds of years
- Preservation may involve curation: active transformation of the data for improved accessibility

What are NOT options for preservation
- Github, Gitlab, Bitbucket, etc.
- Dropbox, Box.com, Google Drive, etc.
- Your personal website
- Your university’s departmental website
Options for Preservation
In one of my day jobs:

Options for Preservation with API
Also Zenodo https://zenodo.org
Getting your API keys from Dataverse
![]()
Adding your API key to your .Renviron
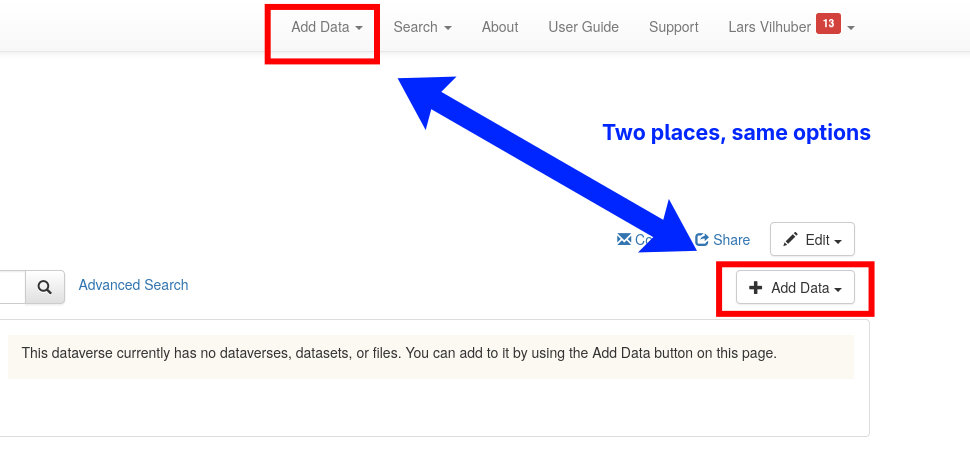
We need a “container”
- Dataverse calls this a “dataset”.
- A “dataset” can hold multiple files.
- While this can be created via the API, I suggest doing it manually (once per project)
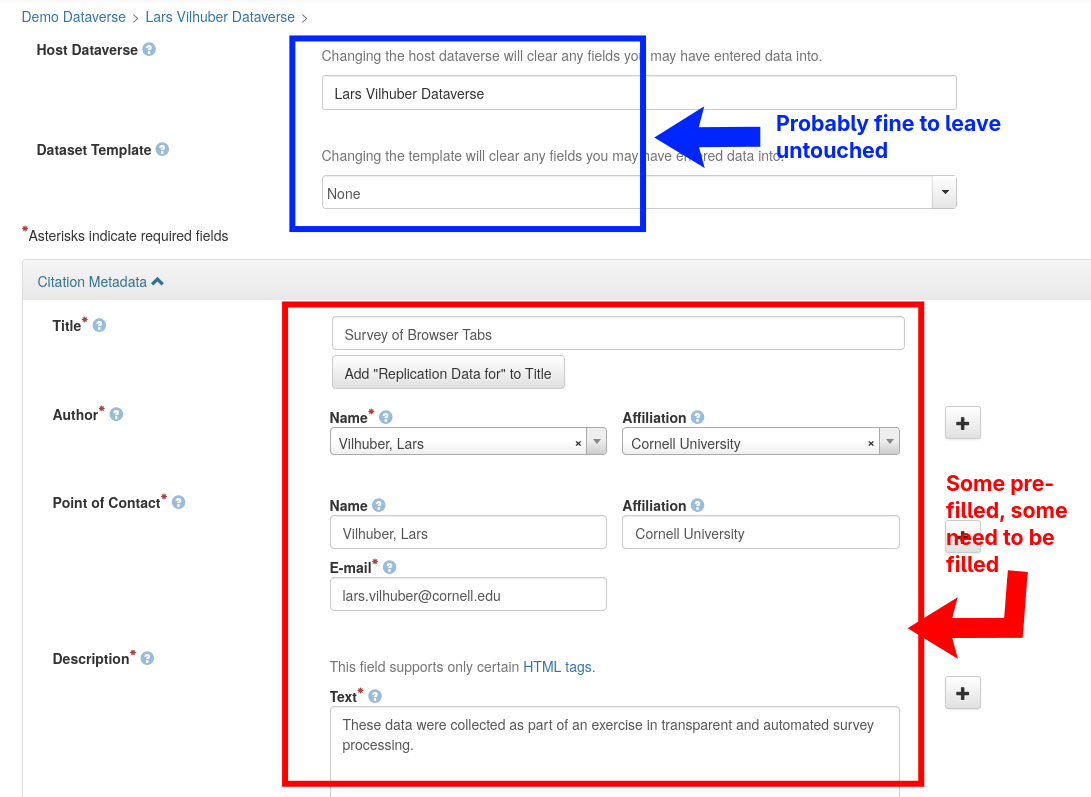
Fill in metadata
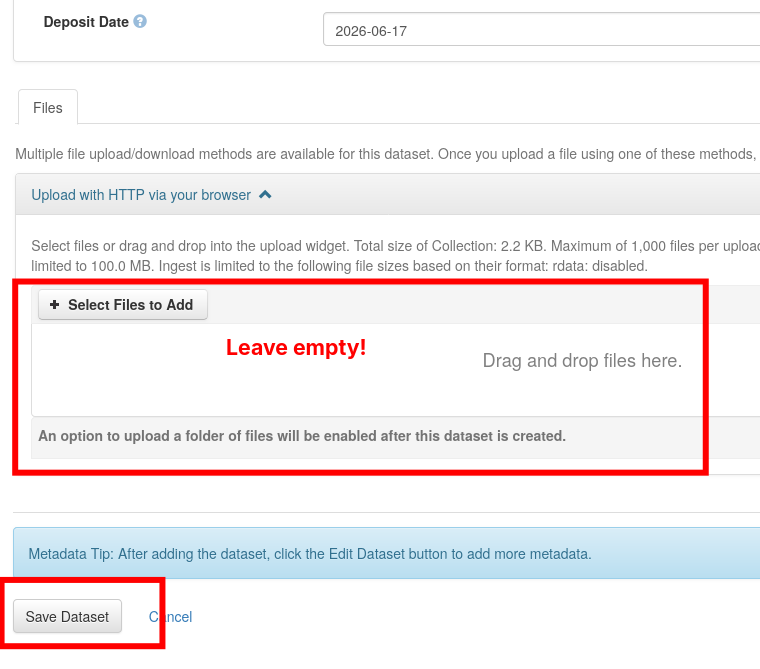
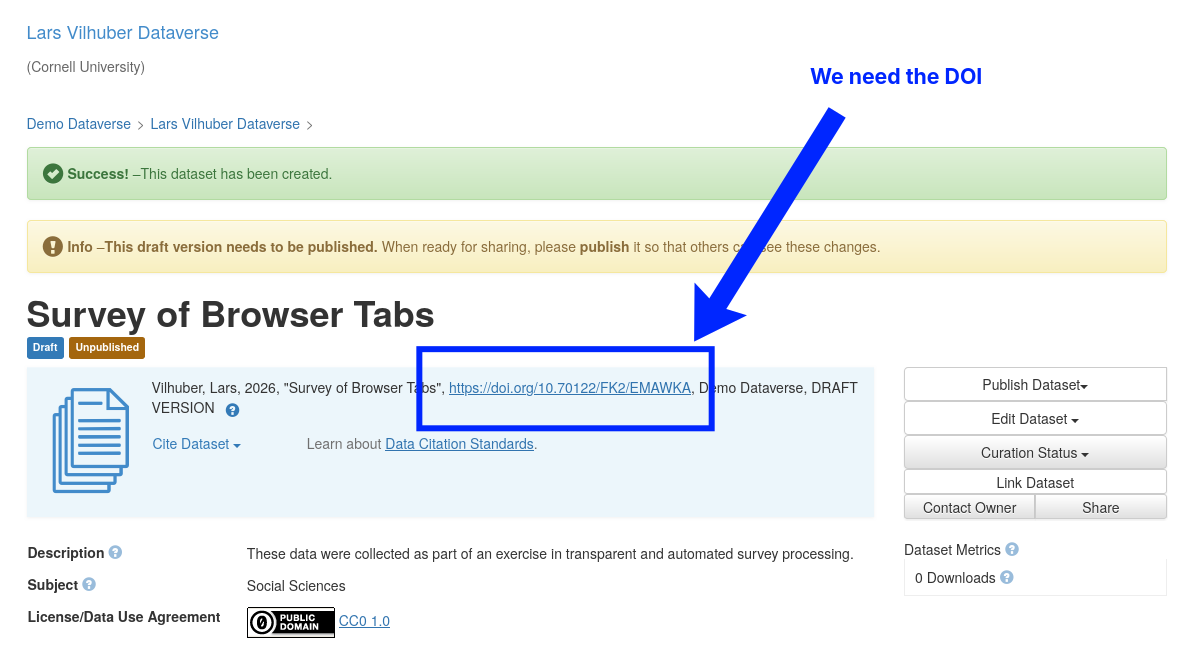
Getting the Identifiers
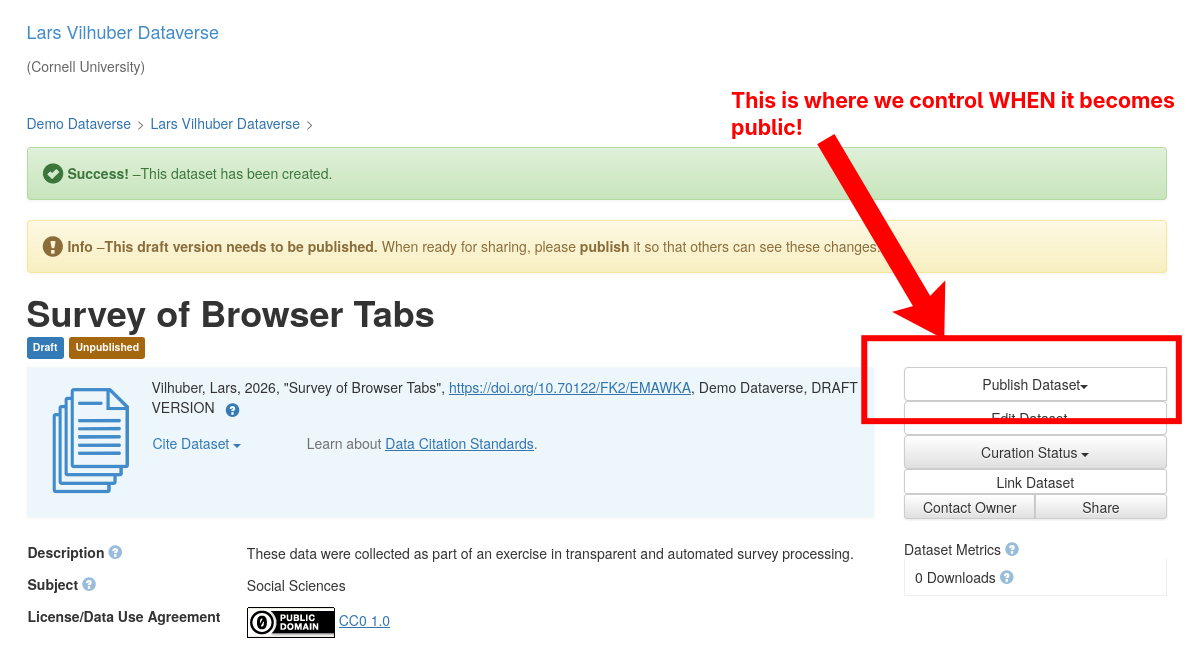
Additional controls
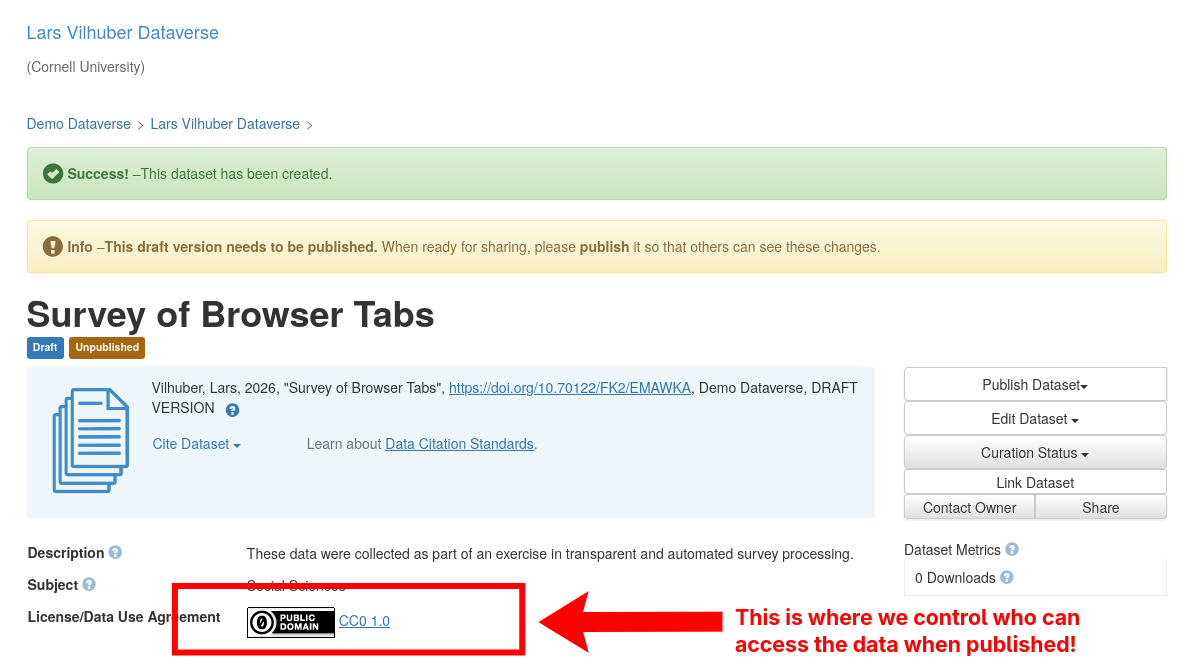
Licensing and permissions
- Terms: For people who wish to download published files
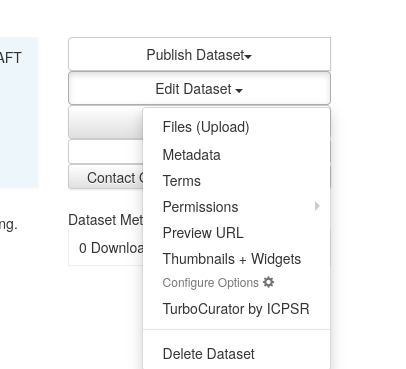
- Permissions: For fine-grained access over who can do what before publication
Permissions
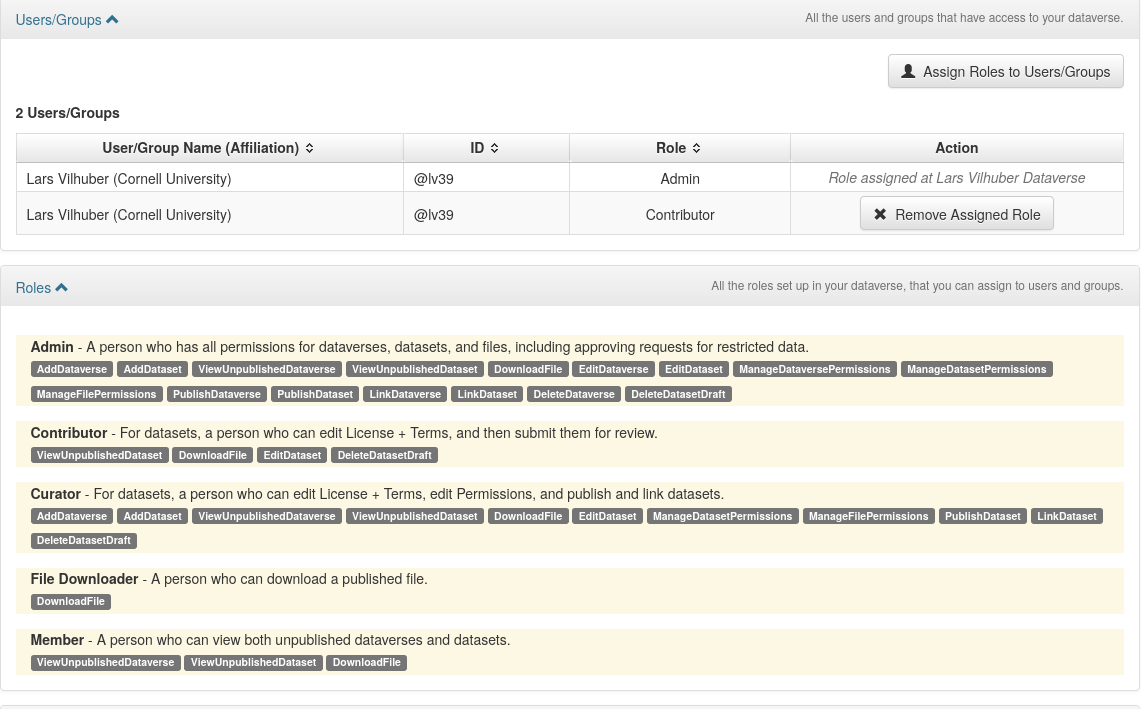
You can designate
- who can upload
- who can edit metadata
- who can publish
Terms and Licenses
- Licenses are broad permissions on how to re-use
- Often CC-BY, see https://creativecommons.org/cc-licenses/
- Terms are more restrictive. Do third party data users
- need to contact somebody
- need to sign a data use agreement
- need IRB approval
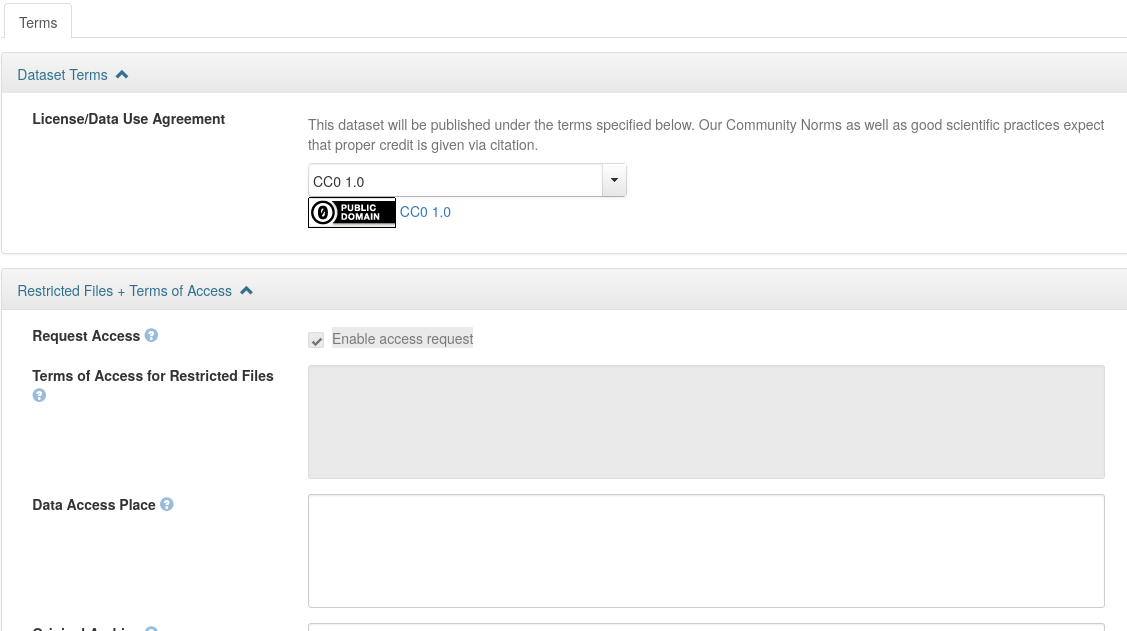
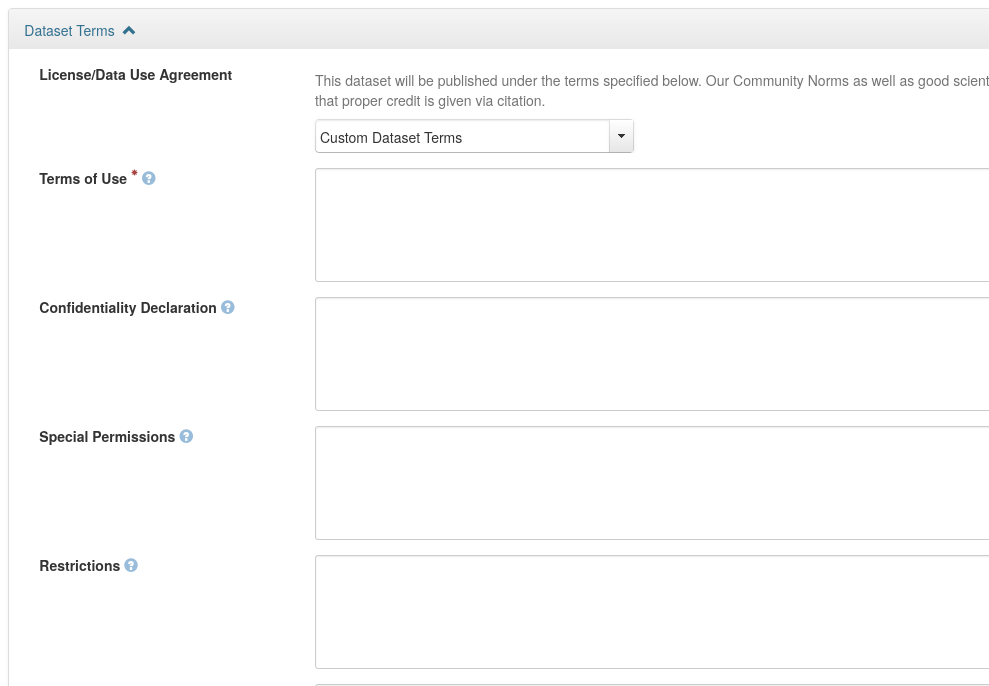
Terms and Licenses
- You can define custom terms (instead of a standard license)
- Strongly suggest talking with University Counsel!
Results remotely
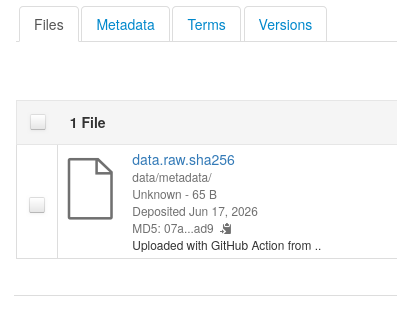
- Filename is preserved
- Pathname is preserved!
data/metadata - MD5 checksum is also present! (less useful for the checksum file!)
A sketch: Transparency Certified
https://transparency-certified.github.io/

Work in progress

Does not prevent all fraud
Toronto researcher loses Ph.D.

MIT student makes up firm data

Footnotes
https://datacolada.org/109, https://datacolada.org/110, https://datacolada.org/111, https://datacolada.org/112, https://datacolada.org/114, https://datacolada.org/118
Jones, M. (2024). Introducing Reproducible Research Standards at the World Bank. Harvard Data Science Review, 6(4). https://doi.org/10.1162/99608f92.21328ce3
See my tutorial on handling of confidential data and reproducibility
Ginn J, O’Brien J, Silge J (2024). qualtRics: Download ‘Qualtrics’ Survey Data. R package version 3.2.1, https://github.com/ropensci/qualtRics, https://docs.ropensci.org/qualtRics/.
Add
.Renvironto your.gitignorefile to prevent it from being tracked by Git and accidentally pushed to GitHub.Eddelbuettel D (2024). digest: Create Compact Hash Digests of R Objects. R package version 0.6.37, https://dirk.eddelbuettel.com/code/digest.html, https://github.com/eddelbuettel/digest.