Lars Vilhuber
Laurel Krovetz
September 1, 2025
We introduce the various modules, talk about best practices, describe what we mean by replication package, and illustrate practically using a toy example.
We discuss how to set yourself up for reproducibility from the very first day of your project. Anything not covered on August 26 will be covered at the beginning of the session on September 8.
How do you check your project for reproducibility before you submit it? We discuss various strategies.
What if you have data you are not allowed to publish? How do you work with it, and how do you share the most of your work? We discuss general and specific methods and strategies.
Once you’ve covered all the bases, how do you document it all? We discuss how to use the template README to document your project. Much of this will recall elements from previous sessions.
This is a recap of the Day N-1 reproducibility module, but with a focus on how to run code reproducibly. We discuss how to create log files, use environments, and the importance of data cleaning.
AI is infusing a lot of what we do. This will discuss how you can produce research that uses AI and APIs, while still being reproducible.
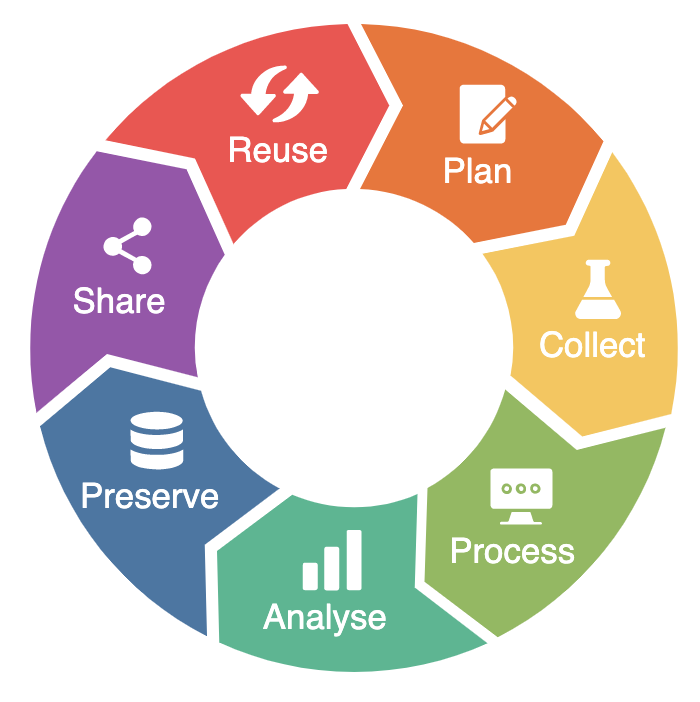
If you create data, or have data that needs to be preserved, what can you do? We start by discussing the distinction between sharing and preserving data, and then look at options that you can embed within your research workflow.
To more efficiently combine processing of data and the writing up of results, a few methods exist. Word is not one of them. We discuss the pros and cons of various methods.
You run your code on your laptop, and it crashes. Use high-performance computing! We disuss when to use it, what the benefits and costs are, and where to use it.
How do you create transparency and credibility when you cannot share the data you use? We discuss strategies both for data collection, data use, and data sharing. This is relevant if you collect your own data, or if you use confidential data.
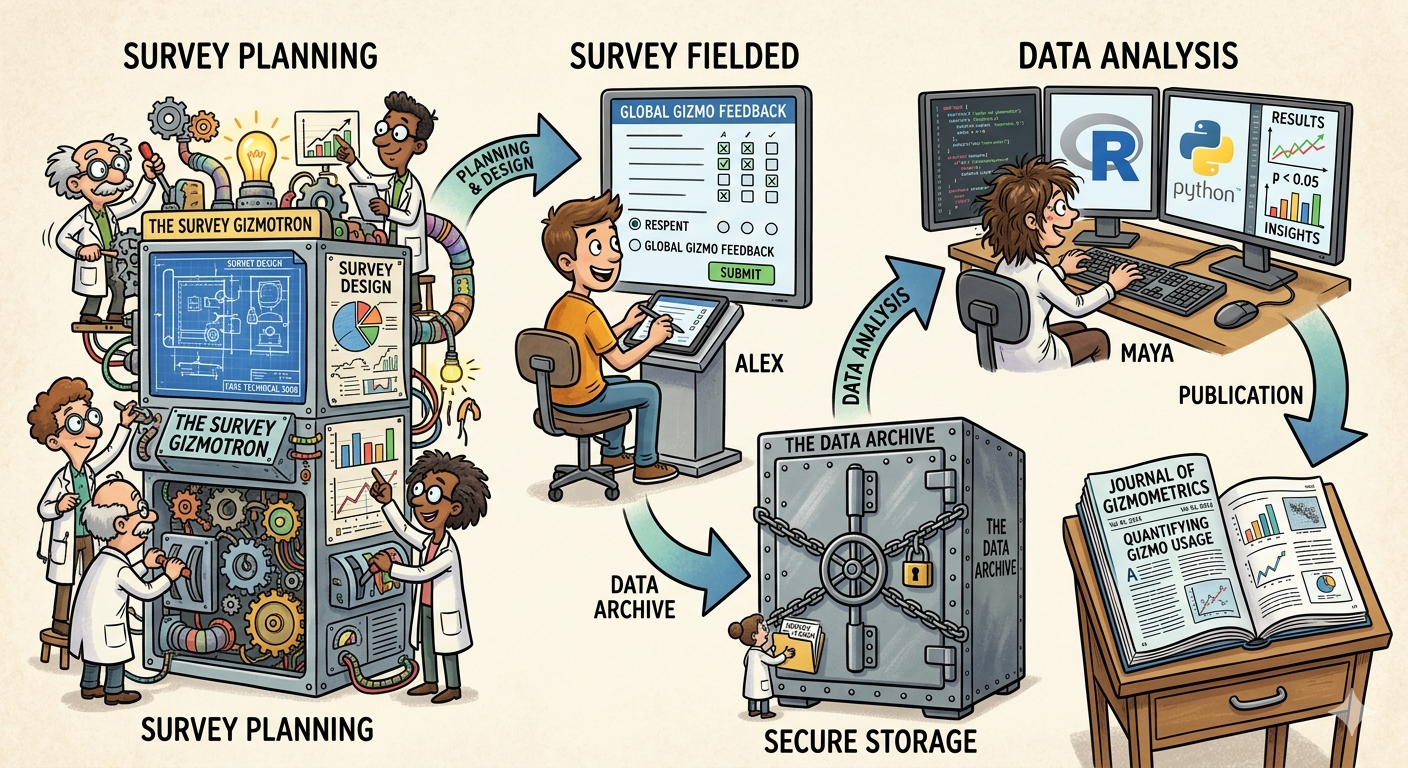
We demonstrate how to preserve raw survey data, while maintaining strong provenance promises. This starts with planning, but also automation.